So, inspiration strikes. It came to me, a visual and mathematical way of explaining the functional information gained in cancer. This should make clear how mutual information of one sort can increase, while mutual information of another sort can decrease.
The beauty of this example is that I can put three things into alignment:
The mathematics of ID, as has been articulated by Marks, Dembski, and most importantly @EricMH here on this forum.
The genetics of cancer, where we have an immense amount of data and knowledge, and which can serve as an excellent “theological control.”
A visual cartoon that shows what is happening with the mutual information, demonstrating the paradox that MI is both increasing and decreasing (in different senses) at the same time.
This is going to come out in a few posts. I hope this is helpful.
Let’s talk about what a theological control is. I think most ID advocates will agree that God is not usually guiding the evolution of cancer by first cause, except perhaps to prevent it occasionally. So any thing we see cancer do, we should be certain is not God’s design. I think also that it does not appear God designed us for the purpose of contracting cancer.
I’m sure there are people out there who might disagree. I think that would be a very hard to justify. Perhaps a YEC might disagree, and call this part of the fall. If that happens, we should discuss it in another thread. Still, it seems to be a good “theological control,” a natural experiment, where we can study how something closely but not exactly) matching our biology evolves.
We are going to use this visual language to make sense of cancer. The circles will each represent a genome, the starting human genome, and the mutated cancer genomes. The area of overlaps between circles quantify the amount of mutual information, related to the sequence in common, between genome circles.
Adding Random Mutation Decreases Mutual Information
This is a genome:
So what happens when a genome is randomly mutated, such as what happens during reproduction or in cancer?
Here, the red circle is the starting genome, and the blue circle is the mutated circle. Mutations cause the circle to shift in a random direction away from the starting point. What happened to the mutual information (MI)? Clearly, the mutual information decreased between the starting genome and the mutated genome.
This is not always the case. In some cases the blue circle can just expand (with an insertion), but for now we will just agree that MI(germline, germline+mutation) usually decreases.
The mutual information between the two cancers is less than the mutual information between the first cancer (or the second) and the germline. So all this is true. This is essentially what @EricMH has been arguing for a long time. I do not disagree. However, this tells us nothing about functional information. In fact, mutual information measured these ways can decrease while functional information increases.
So where do we find the functional information? Paradoxically, it is in the new mutual information that has been created. Didn’t we just decrease mutual information? Yes, so how was mutual information created? Though there was a net lose of mutual information, new mutual information in a much smaller quantity was created. We can see it visually here, to the tiny area pointed to by the arrow here:
Here, the arrows points to the crescent shaped dark green area that is the overlap of cancer1 and cancer2, but not covered by the germline. Equivalently, it is the mutations in common between cancer1 and cancer2 that are not found in the germline. There is a term for this in cancer biology: recurrent mutations, or driver mutations. We could notate this as MI(cancer1 conditional on germline, cancer2 conditional on germline). We could also describe this as the mutations in common between the two cancers, ignoring the sequences shared with the germline.
So now, we can visually see how the paradox is resolved. Mutual information of some sorts decreases, but mutual information of another sort increases. Overall mutual information decreases, but functional information can increase.
Of note, we can observe this in the cancer genome data as mutations that reoccur in different cancers. We know that the overlap is not null.
So now we are in a position to compute how much functional information is gained when cancer evolves. This is a rough calculation that parallels closely the work done by Dembski, Axe, Marks, and every leading light in the ID movement. As has been stated already, they are all making the same argument.
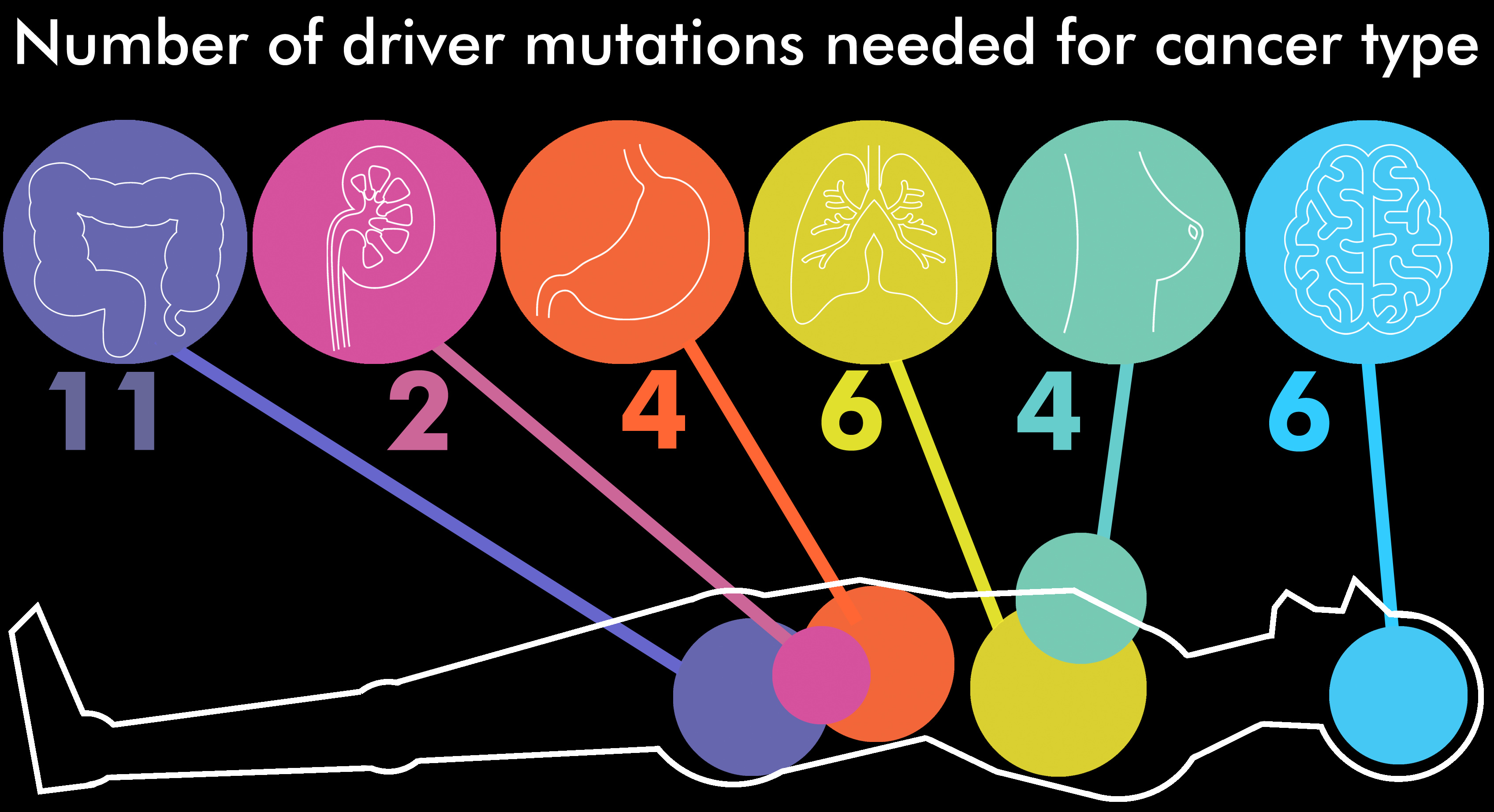
First of all, we know that driver mutations are very rare. Most mutations are not drivers. Most cancers have a lot of unique mutations we don’t find anywhere else. And we can even test if mutations are a step in the pathway to cancer in the lab. More importantly, we have lots and lots of cancer genomes, and looking at all this data we can figure out which mutations drive cancer, and how many are typically required. Here is an important study that does just this, with results summarized in a figure:
So depending on the cancer type, we need somewhere between about 2 (kidney) to 11 (colon) mutations to develop the cancer “function” in a cell. Can we quantify this in bits? Yes we can. This is an approximate calculation, but it in this context it is going to be very close to the true value.
How much information is in each mutation?
It takes about 31.5 bits of information to specify each mutation. We obtain this by computing the log base 2 of the human genome size, which is about three billion bases long. This is approximate. There are reasons to push this number a couple bits up and other reasons to push it a couple bits down. We’ll just assume these effects largely cancel out.
We want to compute the functional information content of the “cancer” function, which takes multiple mutations. How much is that?
As long as the number of mutations is small (say, less than 100), it works to just sum the bits of the mutations. So for some different types of cancer, the functional information gained is about:
2 x 31.5 bits = 63 bits of functional information in kidney cancer
11 x 31.5 bits = 346.5 bits of functional information in colon cancer
6 x 31.5 bits = 189 bits of functional information in lung cancer
Many ID advocates argue that anything that requires more than 50 bits of functional information is essentially impossible in evolution. If ID arguments were valid, we have here demonstrated that cancer is essentially impossible without intelligent guidance.
Some types of mutual information decrease with random mutations.
Other types of mutual information can increase with random mutations + selection.
#2 and #3 are not contradictory statements.
Functional information is identifiable as the type of mutual information that can increase with mutation + selection.
We can compute the functional information of cancer directly based on some well understood biology, and it can be as high as 350 bits.
There for we observe that natural processes can easily produce substantial amounts of functional information.
This means that functional information is definitively not a unique signature of intelligence.
As explained by Robert Mark’s PhD student:
I’ve shown now the way in which this proof is correct, and the way in which it is incorrect. It turns out that some types of mutual information will decrease with random mutations of a starting sequence. Other types can increase. Functional information is the type of mutual information that can increase.
I’ve shown this visually. I’ve provided experimental evidence in the cancer biology. This should now be intuitively clear and and empirically established.
2 Likes
swamidass
(S. Joshua Swamidass)
Split this topic
10
(You can move this to a side comment thread if it’s more appropriate.)
Questions about these two:
When explaining functional information (FI), you initially pointed to the overlap between cancer 1 and cancer 2 that is excluded by the germline, i.e. (C_1 \cap C_2) \setminus G.
But are you defining FI to be equal to this? i.e. FI = (C_1 \cap C_2) \setminus G.
Or are you simply stating that FI is strictly a subset of this, that we identify using deeper biological theories and experiments (instead of definitions), but not all of this is necessarily FI? i.e. FI \subset (C_1 \cap C_2) \setminus G.
Could there also be FI left in cancer 1, cancer 2 that is part of the germline? i.e. \exists x | x \in FI, x \in (C_1 \cap C_2 \cap G)?
What I’m confused about is that it seems to me that while mutual information is a term that can be strictly defined mathematically, functional information seems to depend on empirical experiments, at least in the way people are using these terms. Thus you can’t prove anything about FI by using math alone.
Great question. No, we do not define FI this way. We infer FI from recurrence, and this is usually a valid inference.
Rather, the chances of having the same mutations arising in multiple independent cancers overlap is very low, by random chance alone. I’ve even shown how to estimate the amount of information in common too. These common mutations are called “reccurent” in cancer genomics. In evolutionary terminology, they are homoplastic, or convergent, mutations. In light of the very low likelihood by random chance, at this point, ID makes a the design inference.
However, the design inference does not appear justified in this context, unless someone wants to argue that God is guiding the development of cancer. So this appears to be a clear false positive of the design detection mathematics of ID.
As scientists, that isn’t the whole story. We still want to know how such a low likelihood event takes place. We need to have a good explanation for how this mutual information, these recurrent mutations, arose. The best explanation is that the cancers have common mutations because they both have the same cancer “function.” Cancer genomes, after all, have the same function. Remembering that genotype often causes phenotype, we rationally conclude that the common mutations are those that are causing the cancer phenotype-function. So, therefore, we infer that recurrent mutations are drivers mutations that cause the cancer function.
Is this inference entirely accurate? Without knowing the details it should be obvious the answer is “no”. For every rule in biology there are exceptions. I’m not going to get into that here though. This is usually a valid inference. Nonetheless, it parallels how Durston, Dembski, and Marks define FI. (1) Gather examples of entities with a function, (2) compute their mutual information.
True. What they do, however, is just assume:
life must have very high FI,
the only source of FI is intelligence.
Durston has improved a small bit on this by actually trying to measure FI. However, he misunderstands how to compute FI, associating it with the wrong type of MI. I’ll show that visually in a moment. So he fails at this basic computation in the end, but ID is trying to engage the data. They just do not have enough working knowledge of information theory to even see for themselves when they are in error.
So what can cause high mutual information? It very much depends on the what type of mutual information we are talking about. We can grant a few possibilities.
Intelligence, we can presume is a technical possibility.
Common history / Common ancestry (common starting point before mutation added)
Common mutational distributions and mechanisms (neutral evolution).
Common selective pressures (best explanation for most of cancer FI).
Complex interactions between all of the above.
All these can produce high MI in the right contexts. Of most importance is #2, common history. It turns this explains the vast majority of the MI we see in biology, and because ID is non-commital or opposed to common descent, they are blind to how this affects their calculations. In the case of cancer, if we remove 6 billion bits of mutual information from shared history, the remaining amount is probably FI, and mostly caused by common selective pressures (i.e. natural selection). It is however just a tiny tiny fraction of the total amount MI between two cancer genomes.
The key point is that there is absolutely zero justification for the belief that FI is a unique signature of minds. Zero. What Dembski (and for example @EricMH) is an end run around the hard work of untangling the contributions of all these mechanisms to MI. Instead, they declare that if there is MI, it must be intelligence. Zero justification. Zero tests. Zero demonstration.
This comes out strikingly in Durston’s work. He computes FI wrong, by using a MI that does not take common ancestry into account. He just assumes that all MI must be produced by a mind, and never actually does a coherent simulation of DNA evolution. If he did, and then applied some clear thinking, he would find out that common history explains MI as he computes just fine.
The reason why is because he computes FI incorrectly, by equating it with the wrong type of MI. What we really want is the mutual information computed like this, excluding everything caused by common history:
FI = (C_1 \cap C_2) \setminus G, which correspond to the tiny overlap here (about 60-350 bits, not drawn to scale):
They, however make the mistake of computing FI this way instead, lumping common history as also caused by common function (about 6 billion bits here, and not to scale):
FI = (C_1 \cap C_2) , which corresponds to the overlap here. In our example of cancer genomes, the FI would be computed at about 6 billion bits. As you can see, that equivocation between different types of MI wildly overestimates FI by neglecting the contribution of common shared history.
I want to emphasize, from my interactions with Durston and other ID advocates, I do not think this is dishonesty. They appear to have been blinded by their polemic goals, and self-reinforcing echo chamber. Because most people are lost in the Byzantine derivations of mathematics in general, and information theory of ID proponents too, it is hard for people to break in and enter the conversation with them. They just do not have any practical experience in applying information theory. So it is not surprising that they are making errors here.
This a probabilistic inference. The is not “strictly” anything. There are exceptions. In the end, we do biological experiments, but even these do not establish causality with 100% certainty. What we would say is that:
M \subset (C_1 \cap C_2) \setminus G \rightarrow F
Or that a mutation in that set probabilistically implies that it is functional. Not being in that group probabilistically implies that it is not functional. The arrow here means “implies.” We can test this inference with biological experiments. We find that it is very often correct.
DI, however, sometiems tries to argue:
M \subset (C_1 \cap C_2) \rightarrow F
We can test this with biological experiments too. Find that this inference is most often incorrect (just as predicted by neutral theory). This is not a valid inference.
Remember, @EricMH has argued that the only thing that can cause MI is intelligence? That false claim is what guides him to this error. It is a type of MI, so he just presumes nothing else can generate it. He has not demonstrated this however. He thinks the proofs tell him this, but his application of the proofs would also demonstrate that the 2nd law of thermodynamics is false. Which is to say, his application of the proofs is wrong.
I’ll finally add that we have defined this as sets of mutations in a discrete formulate. In practice, formulate this as bits of information or probability distributions in practice, which allows for more fuzziness. For example, we will not see a given driver mutation in all cancers, but only a subset of the cancers. So all this can be used to handle noisy cases and so on.
Thank you. I have no background in information theory, and this is what I was looking for – an intuitive explanation of what the debate is about. (I still find the claim that high mutual information implies about intelligence to be odd, but I haven’t seen the argument in its favor yet.)
One comment: you note that mutation usually decreases MI between genomes. In some cases, though, MI presumably can decrease and then increase again, when a mutation is followed immediately by a back mutation. This is highly unlikely in a cancer genome, but I’d bet that it routinely occurs during viral infections.



 ) < Intersection(
) < Intersection(