Must be a different definition of FI than he’s claiming, then, because you can’t estimate it from sequence conservation. Further, you can’t separate sequence conservation from non-conservation just by looking at two sequences. You would at least have to compare several sequences that diverged at equal ages, in order to separate conservation from simple divergence. You can’t say that there’s more FI in two proteins that diverged 1 million years ago than in two that diverged 10 million years ago just by noticing that the first two are more similar. But that’s what Gpuccio does.
But he isn’t measuring conserved sequence similarity. He’s just measuring sequence similarity, period. Durston et al. at least measured sequence variation for a large taxon set. And of course they didn’t claim to measure FI either. Or does Gpuccio want to redefine FI to be whatever he measures?
Surely you understand that merely saying Gpuccio got an idea from Durston and his co-authors does nothing to substantiate that what Durston et al. does makes any sense?
The point is of course that conservation doesn’t actually tell us what fraction of sequence space has some degree of the function of interest. Setting the threshold for function at the level exhibited by conserved positions is an act you are doing when analyzing a sequence, it is not thereby making sequences below that threshold nonfunctional.
Conservation might tell you that in the immediate sequence-neighborhood the conserved residues are the most fit ones (hence why they are being favored over other variants), but that does not allow you to conclude unseen (non-conserved) variants at those sites would not strictly also be functional, though to a lesser degree.
And it certainly doesn’t tell you that the extant sequence could not have evolved incrementally from a more probable ensemble of sequences.
For these reasons, again, conservation just isn’t a valid way to measure FI, and it therefore can’t be used to infer what we normally mean by the term design. Design which, btw, doesn’t work in the way ID proponents seem to think. It just isn’t this mysterious ability to somehow know without a lot of learning and trial and error, how to solve a complex problem with extremely rare solutions in sequence space. Case in point, the password problem. Notice how design doesn’t solve it. If there is no way to incrementally move towards the correct password, design does no better than evolution and you’re forced to just try random, brute-force guessing.
The design inference from FI fails at every level. You’re not measuring FI, even if you were you couldn’t rule out evolution, and design can’t solve problems evolution can’t either because design is itself a learning algorithm that has to increment towards solutions.
Where do Durston et al state that “conserved sequence similarity can be used to estimate FI”? The closest I could find was the following:
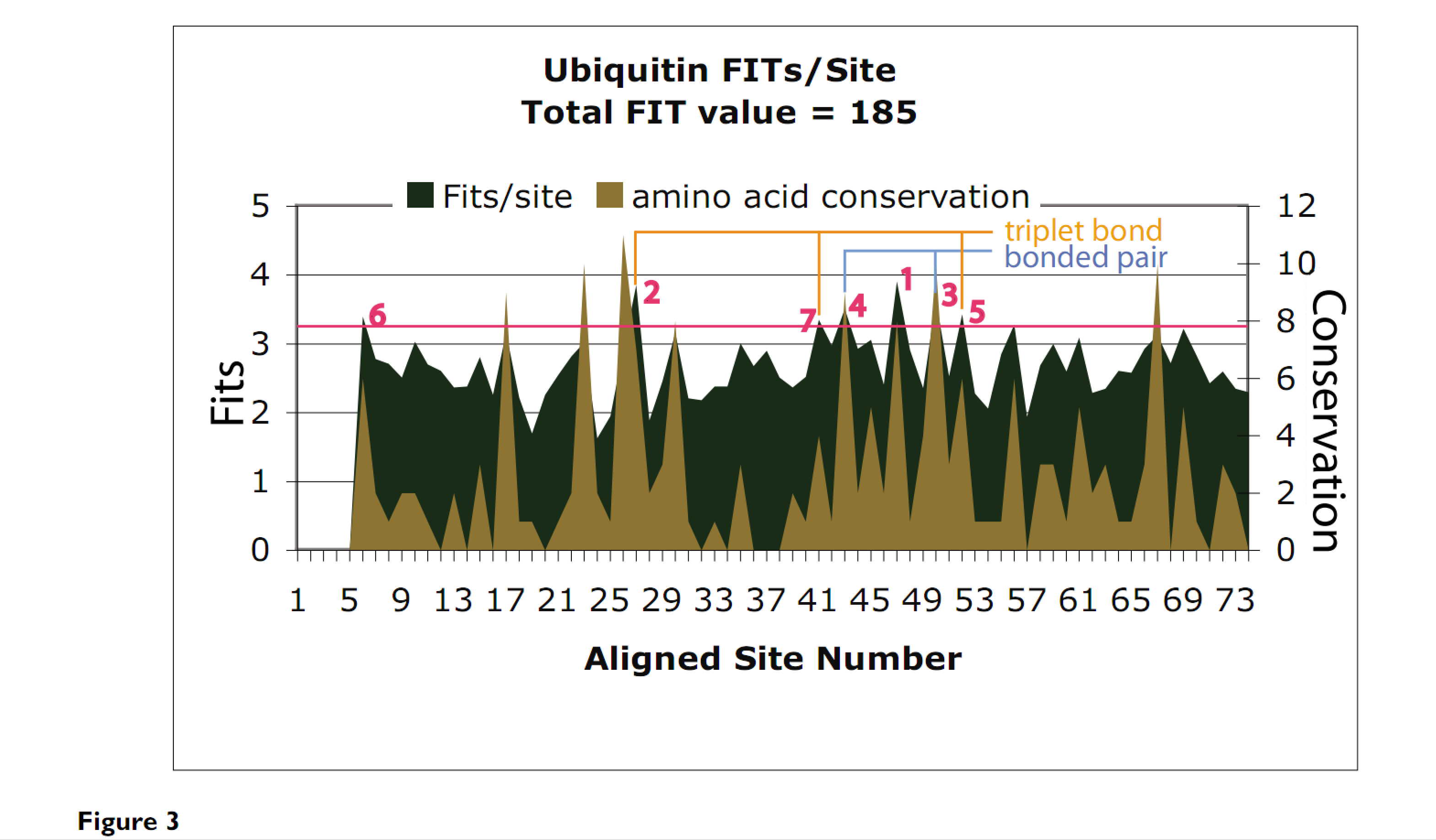
From Figure 3, it can be observed that a high conservation value usually corresponded to a high measured FSC value. The measurement is also affected by the number of amino acids observed which could be different for different sites. For example, site 37 shows 20 observed amino acids, but still a relatively high value of 2.9 Fits. Conservation of a site reflects the degree of variations which is affected by both the number of observed amino acids and their frequency of observation in the alignment [12]. For example, if a site is observed to be dominated by only a few amino acids even though all the amino acid types are observed, its measured FSC could still be high.
That something merely “usually corresponded” with something else does not make it a good estimator for it, particularly when it is explicitly noted that other factors may heavily affect the degree of relationship.
Certainly Figure 3 does not support any contention that conservation can be used as an estimator of Functional Sequence Complexity:
This is quite apart from the fact that the measure of conservation that Durston et al was comparing is very different from the measure that Gpuccio is asserting.
In fact it is hard to see any overlap between this paper and Gpuccio’s methodology – so its citation would appear to be a complete red herring.
They do no work to show that in fact FI is measured by conservation. It’s is simply assumed to be the case.
They simply can’t claim that one corresponds to the other, neither usually, frequently, some times, or ever. Nowhere in the paper is the assumption actually tested. And I must reiterate that even if you could estimate the FI for a particular function, that still wouldn’t tell you whether it was likely to evolve or not. Because, again, a high FI value still doesn’t tell you that the extant sequence could not have evolved incrementally from a more probable ensemble of sequences with other, more probable functions.
So not only can’t they claim that it’s the same, they don’t claim that it’s the same. The paper says nothing about FI and doesn’t try or claim to say anything about FI.
A random 1,000 base pair sequence will be highly improbable. Once again, you would conclude that a random sequence is both high in FI and complex.
That’s false. If you start with a random sequence and randomly change it over time you will get high FI using Gpuccio’s method. It has nothing to do with function. It only has to do with how many differences there are between the sequences.
Well no, I’m sure Gilbert is aware that a sequence also has to be functional. A sequence can’t have high FI just from being improbable.
No. I think that’s a strawman. I’m sure they are both aware that a sequence has to be functional too to have any FI. That’s just how FI is defined. That they’re mistaken to think sequence similarity can measure FI doesn’t mean they aren’t aware that FI is necessarily also tied to function.
And anyway, a sequence doesn’t get high FI by being different from the human sequence. It gets is by being similar, since FI is measured by similarity to the human sequence.
Actually the probability that it can perform a biological function is about ~65% in prokaryotes, since a random 100 bp sequence has a 10% probability of being able to function as a transcriptional promoter.
No, he doesn’t. Mozart didn’t just one day wake up and start composing with zero exposure to music beforehand. His dad was a composer for crying out loud. His mother’s father was a musician too. He was taught and benefited greatly from a famility of skilled musicians. He had a childhood. Being talented doesn’t mean having magical powers. In fact being talented frequently means having a great ability to learn, and becoming truly great also frequently means having opportunities others don’t. It doesn’t mean and never did mean being given divine inspiration to magically solve complex problems by revelation without having to go through lots of learning and trial and error.
Mozart also didn’t just wish up a piece of music. Composers iterate on them. A lot.
I have a question, especially for @Giltil but also others in this discussion. Has Dembski, or Marks, are any of the ID leaders offered any sort of criticism or discussion about gpuccio’s methodologies? Preferably, a substantive comparison that highlights differences, similarities, and whether gpuccio is really onto something (in their opinions). Like most here, I am of the opinion that there are substantial differences, and I am curious as to what the ID community (as opposed to critics) thinks.
If this has been answered elsewhere in this thread (or on PS), I apologize for missing things.