Pretty good article @jongarvey…
http://potiphar.jongarvey.co.uk/wp-content/uploads/2018/10/randomness.jpg
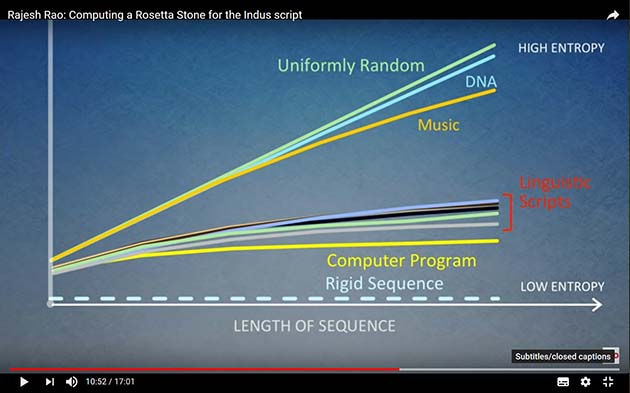
The diagram, though, seems also to bear on the long and highly technical discussions Joshua Swamidass and others have had on Peaceful Science (and before that, on BioLogos ) with various Intelligent Design proponents, in relation to the information content, or lack of it, in DNA. In that context, what obviously drew my attention was the closeness on this slide of the line for (genomic) DNA to that for “uniform randomness.”
What is remarkably about this @jongarvey is that your discussion of Information Theory, coming from a physician-theologian, is just about entirely correct (have to caveat somewhat).
The nature and context of the illustration clearly leave a lot about its derivation unexplained. How large a chunk of genome was sampled, for instance? But whilst I can imagine some Epicurean gloating that the DNA line shows that random neutral changes can easily produce the human genome, that cannot be what it shows. The question had me downloading a few articles on “DNA compression” to see what light they could cast.
My articles showed (not surprisingly) how complex the question is. There is a practical interest in compressing DNA data, purely for economy of storage in databases, and some papers offered methods of doing that. On the other hand, mathematical papers emphasised the difficulties of compressing genomic data, therefore reflecting its high entropy.
One paper rightly reminded us that “randomness” is always contextual, not absolute – a point I’ve often made myself. For example, one way of compressing data on multiple human genomes is to compare their differences from a reference standard, individuals differing by only 0.1%. On this measure, the human genome is very highly organised and so compressible, by virtue of the efficiency of the human reproductive mechanisms in maintaining humans as humans. This, however, is a different context for assessment than comparing a genome with a random string of bases.
And:
What makes a sound file bigger and less compressible is that, as well as the information in the score, it contains all the variations in musical expression – time, volume, attack, vibrato and much more – together with much information from the acoustic environment itself, such as reverberation and echo. An actual orchestral performance, produced by dozens of intelligent interpreters of the score under a skilled conductor, contains much more “designed” information than the written score, and yet this paradoxically brings it closer to the “uniformly random” character of meaningless noise.
And here too:
What makes a sound file bigger and less compressible is that, as well as the information in the score, it contains all the variations in musical expression – time, volume, attack, vibrato and much more – together with much information from the acoustic environment itself, such as reverberation and echo. An actual orchestral performance, produced by dozens of intelligent interpreters of the score under a skilled conductor, contains much more “designed” information than the written score, and yet this paradoxically brings it closer to the “uniformly random” character of meaningless noise.
This the grand paradox of “information.” They highest information density objects are indistinguishable from random noise. Information theory is really not that difficult to grasp, unless one is pre-committed to an untutored intuition of it.
{kind=link}