It seems that your conclusions are based on intuition instead of any hard calculations. Every scientist starts with intuition, but hypotheses need to progress beyond that stage. I don’t see this progress with what you are presenting. It seems to boil down to “Wow, look how complex that is”, and then stops there.
I don’t see how you can do that for proteins that evolved hundreds of millions of years ago because we don’t know what those conditions were. At the very least, we would need the ancestral genomes and environments.
Here is an example of an RNA ligase the emerged from randomly assembled RNA monomers:
I don’t know why you are stuck on 100% heads when any order of heads and tails are equally improbable. On top of that, I don’t see any analogy to biological systems.
That’s not how evolution works. You might as well say that it was too improbable that my genome is nearly identical to sequences found in my parents’ genomes. What are the chances that 6 billion bases would randomly line up with my parents’ DNA? This seems like the type of sleight of hand you are using here.
The 100% heads is a macrostate, 50% heads is a macrostate, one macrostate is astronomically more improbable than the other. You’re doing the analysis purely in terms of microstates, and that’s not how casinos, for example, bring home the bacon. The probability of macrostates is important and this is evident in casino management and other applications of the law of large numbers.
The biological examples were discussed earlier in Change Tan’s examples. DNA wouldn’t be of much use without homogenous characeristics like homo linkage. Same for homochirality in amino acids.
Thanks for the RNA article and the comment. That’s worth looking into.
I think I would give @stcordova a pass in this particular instance. I don’t think he has chosen the best set of ZFP sequences to use, and it may be that he is slanting things towards an antievolution end. But he could do worse.
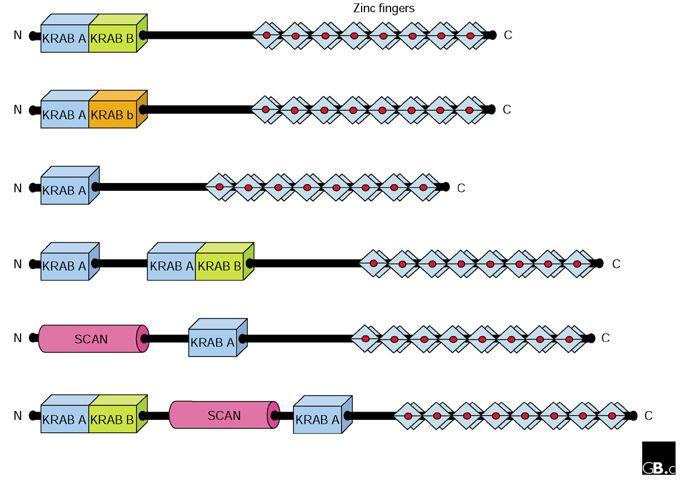
Primary structures of typical KRAB-containing zinc-finger proteins, illustrating the range of domains they contain. Note that the number of zinc fingers among proteins in the family is very variable, ranging from 4 to over 34; only 8 are shown in each structure here, for simplicity. The KRAB domain consists of the A and B boxes; some proteins contain a variant called the b box. Some members of the family have a leucine-rich SCAN domain that allows homo- and hetero-dimerization with other SCAN-containing zinc-finger proteins. Several proteins have been found corresponding to each of the structures shown; they therefore probably represent distinct structural and functional subfamilies. N, amino terminus; C, carboxyl terminus.
I agree - it is an interesting idea and I expect it to produce valid results.
But both it and the bible code tool work by displaying sequences in a 2D array, and given the authors of skittle I expect the output to be used to support similar conclusions to that claimed for the bible code.
This is totally different @roy, text would not produce this pattern in this display. It is well know that there is a high number of repeats in DNA a several scales. This is not a feature of text.
This is not a sign of design, of course, but several well know mechanisms.
The bible code tool displays text as a 2-D array. It has been used to highlight hidden features of the letter sequences. These features are expected because of probability, but were nevertheless claimed to be evidence that the text had divine origin.
Skittle displays genomes and proteins as a 2-D array. It has been used to highlight hidden features of the nucleotide and amino-acid sequences. These features are expected because of known DNA mechanisms. Do you think Seaman and Sanford will not claim that the patterns they find using Skittle are evidence of divine origin?
Let’s not forget Sanford’s Mendel’s Accountant program which was written so any starting population with any chosen parameters rapidly went extinct due to “genomic entropy” degradation. So the idea of Sanford writing software specifically designed to support his YEC position is not far fetched.
Well he did not in this paper. The analogy you are drawing is weak because the Bible code picked up spurious patterns. Skittles is picking up real patterns.
But the exact same situation could have arisen by having 2 chess engines that randomly select from among legal moves play 2 games. The games would reach 2 positions which could not be reached from each other by any sequence of legal moves.
Intelligent design is not required for the moves, only the rules - AI self instructs the tactics and strategy.
We know a human mind is capable of formulating a strategy to win at chess. Check
We now know that a completely blind process with selective feedback can mimic a human mind to win at chess. Check mate.
Now an ID proponent might reply that the AlphaZero team designed the machine learning system that self-instructed. As a Christian who Affirms the Science of Evolution, I would point out that the analogy is subtly but deeply wrong.
Just as the AlphaZero team designed the ML system, God designed the evolutionary processes that we see. Science shows us how those evolutionary processes operate, both in general and in specific instances. However, detecting the hand of divinity is not part of the scientific toolkit; that requires other epistemological approaches combined with a healthy dose of trust/faith.
Off-Topic, but … In my amateur efforts to allow Economic Game Theory to actual games people like to play, random play is a useful baseline for evaluating the skill of players. A human with very little skill may not do much better than random play. A skilled player will be much more able to identify good moves most of the time.
Sorry to wander off, but I never thought this topic would ever come up here.